Benchmarks Are Hard, Actually
Lessons from scaling LLM evals on GameCube games

After starting out as an excuse to play around with MCP, EmuBench is now able to:
Spin up 50+ concurrent GameCube instances
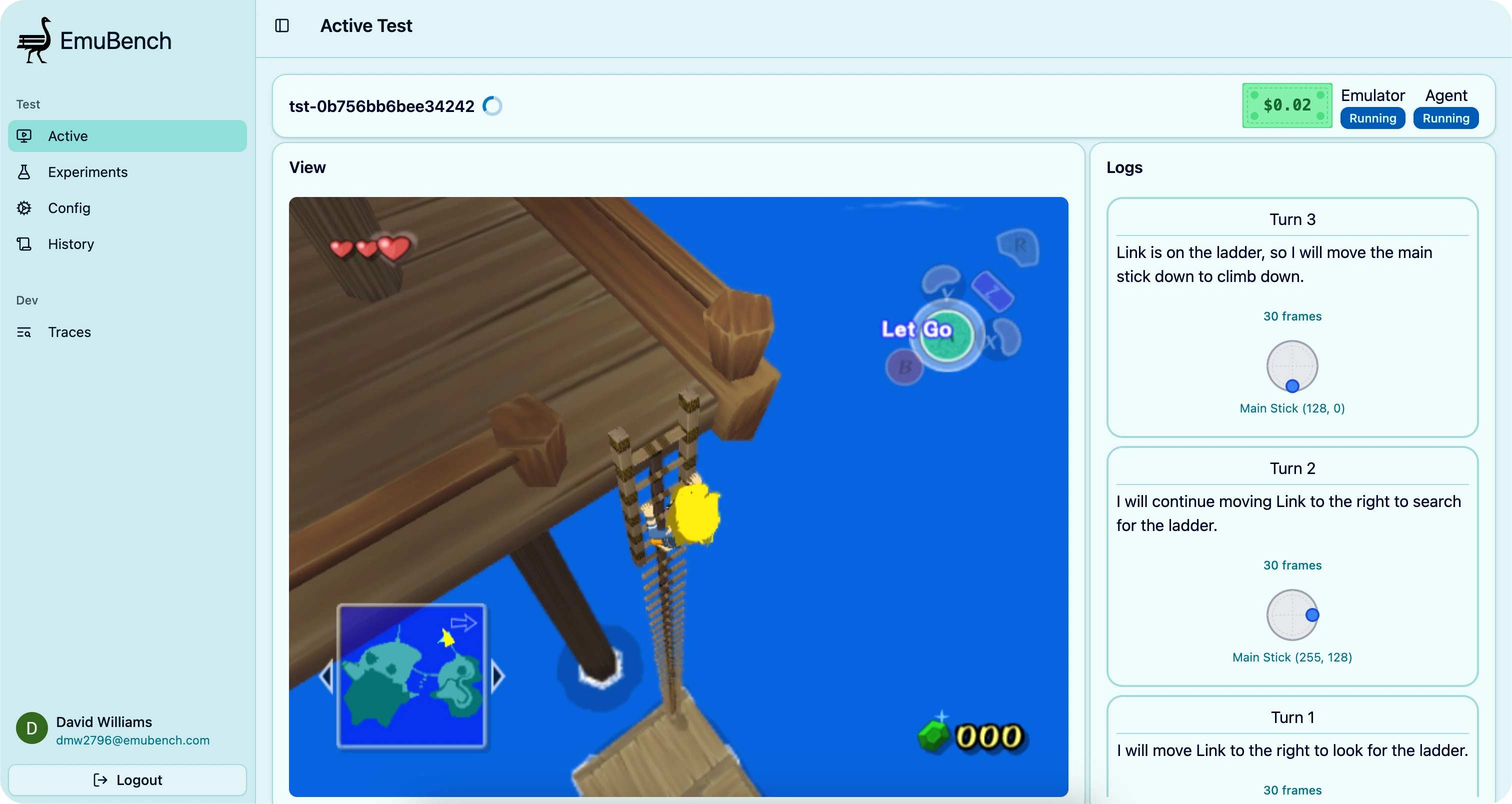
Collect and send detailed game information to any frontier LLM, allowing the models to think and take any action a human player would
Show both high and low-level views of any running test or suite of tests
Generate p-values and other statistical information about the performance of different models or configurations relative to each other
All from a sleek, mobile-friendly UI! It’s been a lot of fun to build, and makes for a pretty entertaining demo.
This writeup is mainly focused on the development of some of the newer features in EmuBench, along with a lot of really interesting challenges I’ve run into along the way while working with these models (+ a bit of a ramble on coding tools/AI capabilities). I plan to soon do another writeup diving much deeper into the actual data I’ve collected, results I’ve found, and what I think it means for where we are and where things may go (as any good benchmark should tell you!)
Experiments
I’ve been building for months towards the ability to scale up my tests and actually collect enough data to find interesting trends. This has resulted in the main new large feature of EmuBench, “Experiments”.
As the extremely creative name implies, an Experiment tests a hypothesis and uses common statistical methods in order to understand if different configurations result in different success rates. I’ve expanded the configuration options to be quite diverse, allowing Experiments to compare system prompts, models, inference parameters (things like temperature), different ways of constructing context, memory, and the impact of different visual effects (shaders).
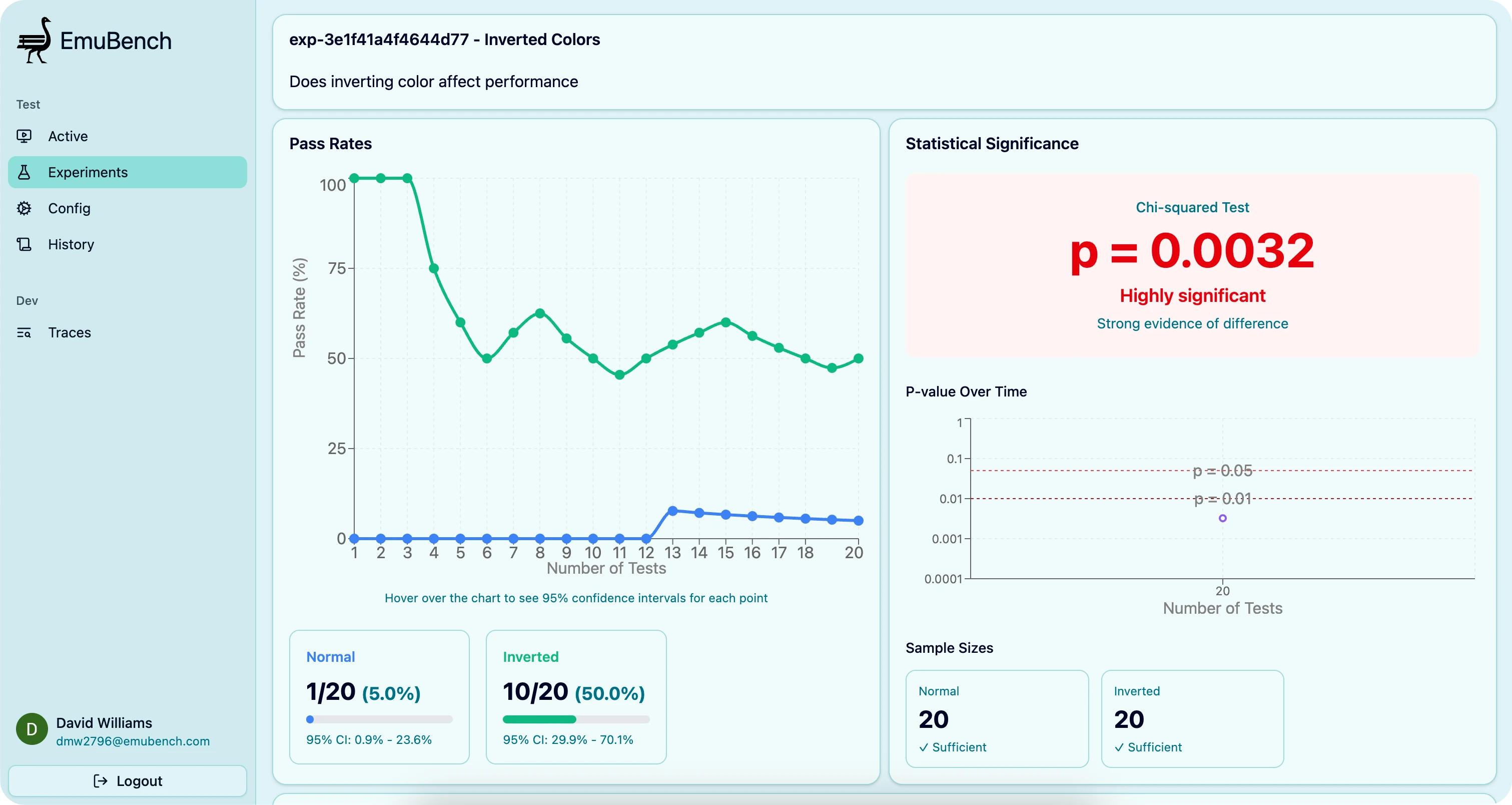
For example, this Experiment found (counterintuitively) that inverting color actually significantly improved Claude Opus 4.5’s performance on a simple “Find and climb the ladder” task
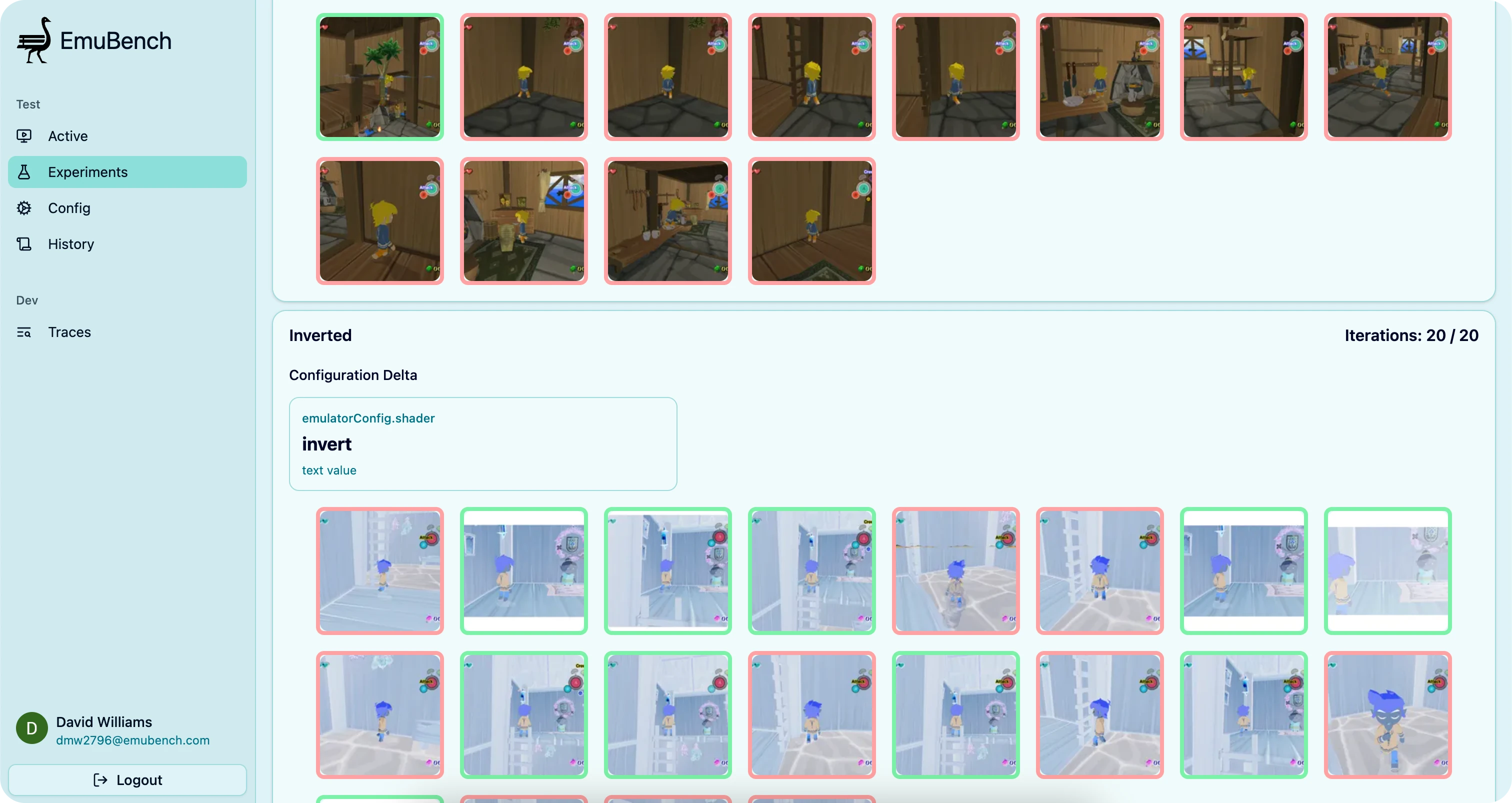
I had to do a lot of cleanup and optimization before scaling everything up. Tests took way too long to start up, state was all over the place, and I needed to more gracefully handle a variety of failures. I was also continually adding other features while building this out, so it took a while to get things in a place where I was happy and could easily kick off an interesting Experiment from my phone.
Tasks
For most of my testing, I had been using one of the first tasks I had set up: “Find and climb down the ladder”. This starts the model at the very beginning of Zelda: Wind Waker with the player on a wooden platform, and tasks the model with finding and climbing down the ladder on the side. This task had a lot of good properties:
Required non-trivial visual understanding, as the ladder was not immediately visible and hard to see from many angles
Easy to verify, just need to check if Y position goes down
Has some distractions (NPC immediately visible)
Non-zero success rate across models
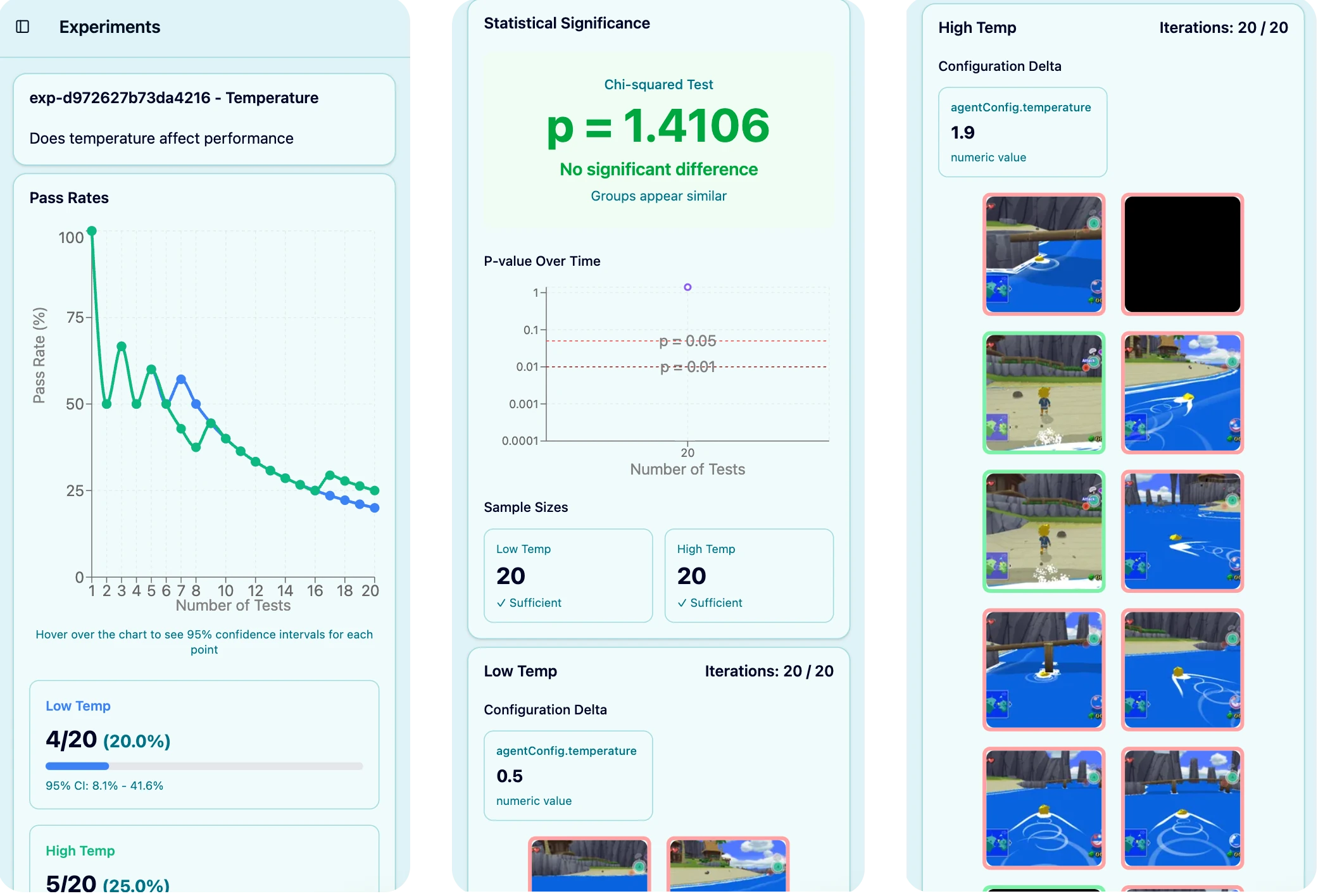
But once I had Experiments built out enough to do some larger runs (30+ samples), I kept getting strange results: older and dumber models were succeeding at _much_ higher rates than newer and shinier ones. I had one Experiment where my results showed Gemini 2.5 Flash being statistically better at solving the task than Gemini 2.5 Pro with a p value of 0.001.
I was struggling to understand how I could have issues with my code/setup that could lead to this type of outcome. I had built out a view that let me easily replay a specific test so I could better inspect what happened, and when I started looking at the successes from Gemini 2.5 Flash the issue became obvious: the task could be beaten by just continually moving right.
Just like in Luigi wins by doing absolutely nothing, sometimes very simple strategies are optimal. Gemini 2.5 Pro (and even Gemini 3) had lower success rates because they tried to do “smarter” things like moving the camera around to look way more often than 2.5 Flash, which loved to just pick a direction and keep going. This was hard to spot when I initially created the task because as the character moves right the camera adjusts too, and the movement curve this creates turned out to be just right to move from the starting position to the ladder, which was back and to the right.
Other tasks I had been using had similar results where dumb models were getting better results than smarter ones, but thankfully the issues were less subtle. Another task starts with the character in the water facing towards the open ocean and prompts the model to “swim to the shore”. This requires realizing there is no shore ahead, turning around, and then seeing and swimming towards the island:
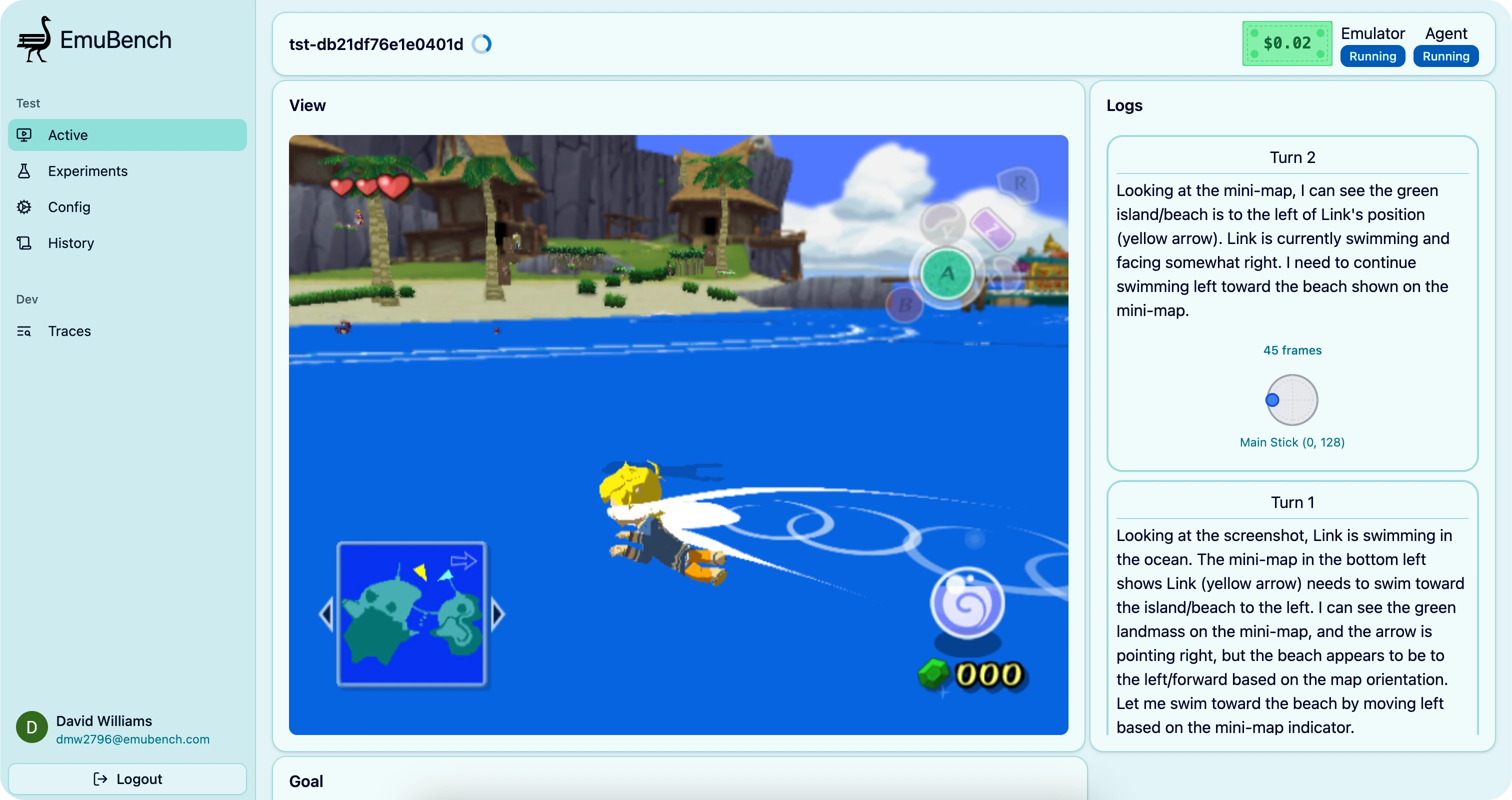
The Y position I was using from memory is just set to 0 when Link is in the water, so the test would report success as soon as Y !== 0. Turns out the dumber models were taking longer turns (more frames per input) and drowning, and when they respawned back on the dock this would satisfy Y !== 0.
Overall, this experience has definitely given me an appreciation for how hard it is to scale up even simple sounding tasks. Had the results aligned with what I expected (Gemini 3 dominating), I likely would not have done nearly as much manual validation and would have missed some of these issues. I want to eventually use EmuBench for RL to fine tune models using rewards from completing tasks, but I can see how easily my time and money could be wasted if I don’t discover and fix all of these issues with the tasks, as the models would just learn to reward hack.
Similar to reward hacking, I also ran into other very interesting and undesired behavior from the latest and greatest models.
When Learning is Actually Bad
When Gemini 3.0 was released the other week, I was excited as I finally had EmuBench in a really good spot. After getting the new model added to the UI and server (took all of 5 minutes), I ran a single test to be sure I had the config correct before going for scaled up Experiments. Almost immediately I started noticing a big problem: it was sending back tool calls directly as text in its response, instead of actually invoking the tools it was given.
I’ve been using the Vercel AI SDK for this project, and I’ve really appreciated how easy its been to use. I work on a very large scale SDK for my day job, so I have deep respect for how well this library works. But given how fast everything has been changing in the world of LLMs (o1 and “reasoning” models aren’t even a year old!!), it’s impossible to not eventually run into issues where newer models don’t plug in the same way you expect and the SDK fails. I remember trying to BEG older models to output valid JSON, and even with EmuBench I’ve seen most models not respect my tool schema ~1-2% of the time.
But this particular issue was kind of fascinating. The first turn Gemini took, it properly invoked the tools in the way the AI SDK was expecting. But after one turn, it would start sending back text like `Tool: sendControllerInput called with { “x”: 128, y: “255” }`with no tools actually getting invoked. This seemed like a weird format for it to be expecting to call tools with, specifically the `called with`. I quickly realized this was exactly the format I had been using in the context I gave the model about the past N turns it had taken. This was a bad form of in context learning where the model learned to call tools incorrectly when given enough examples.
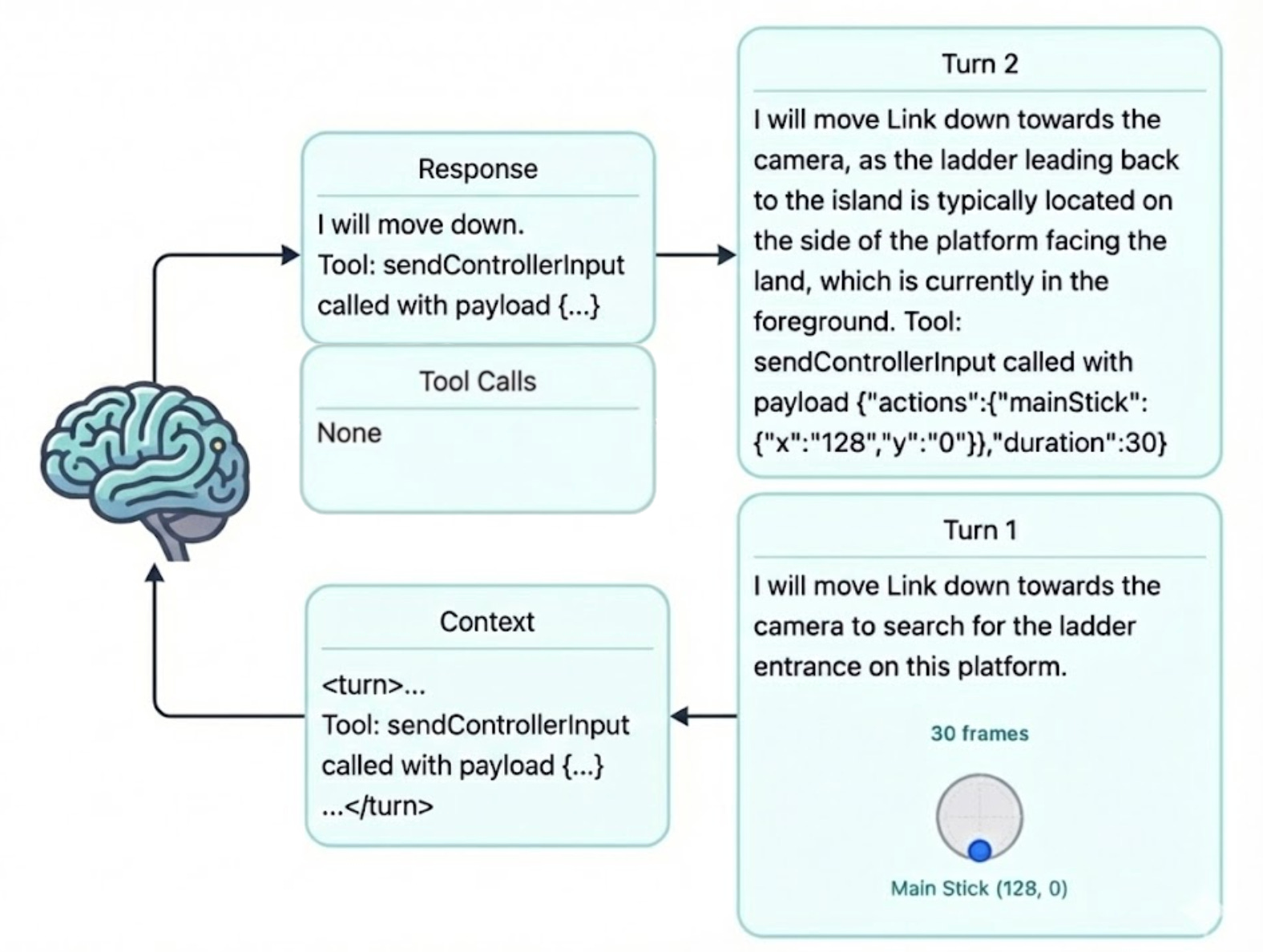
Despite the incorrect way of responding with a tool call, the model’s text description of what it is trying to do is correct and really looks like “reasoning” to me.
When I modified the prompt to wrap this part of the history in `<informational>` and specifically mention this is not how it should call tools, it worked as expected. I’m guessing there may be some way to tweak how I am leveraging the AI SDK or maybe upgrade to a newer version of it that might be better than this hack, but I haven’t looked too deep into it.
Either way this has made more clear than ever to me that these AI models have extremely unexpected failure modes. Unfortunately I find that over and over it feels like the only way to see what will happen is to try it. While that’s kind of an inherent feature of any complex system, its especially true with LLMs.
What’s Next?
After 413 commits across 4 services and 8 months of work, EmuBench is now at the point where I can run interesting tests at enough of a scale to get statistically significant insights. In particular, I am interested in:
How do different visual effects impact model performance? Are some models more affected than others?
How well can performance be improved just by modifying the system prompt using evolutionary optimizers like GEPA?
Do any “easy to implement” long-term memory systems (no test-time fine tuning or anything crazy like that) meaningfully help models on longer tasks?
Same as last time, if anyone has actually read this far and is interested in playing around with EmuBench or has any thoughts please reach out!
Code:
emubench-ui
emubench-serv
emubench-agent
emubench-dolphin
Notes on AI Assisted Coding + Capabilities
In contrast to the more disappointed note I left last time on my experience using agentic coding systems, newer models and tools like Claude Code are a genuine pleasure to use. While still full of issues, these systems are now able to take on a more useful range of tasks. Just off the top of my mind, Claude Code and Copilot excelled at:
Adjustments to the look and feel of UI components
Writing decently complicated C++ functions with well specified inputs, outputs, and purpose
Helping debug complicated bugs in the emulator, which is a very large codebase
Now, if anyone digs into the code in my services you will find areas that are probably puzzling. I’d say maybe… 15% of it by now has not been closely inspected by me, and I bet I couldn’t tell you much about the details. But in these areas, that doesn’t really matter.
The performance of these systems in recent months has switched from being a net loss to a net gain on saving me time. Early this past summer I spent an embarrassing amount of time begging Claude Code to write code and debug its work. Sometimes it would succeed, but its failure rate was high enough that if I’m being completely honest made it a drag on my productivity. Especially on my lazier days where I didn’t want to expend much mental effort on fixing the agent’s work, it would get into a loop of always creating new bugs and sometimes fixing others.
But Claude Sonnet 4.5 (and now Opus) inside of Claude Code are very good, as long as you can tolerate some instability, jagged outcomes, and it’s not very important for you to have deep knowledge of how the feature works. The last point is probably the most important and what holds me back from using these systems more at work. For me (and I’d imagine most people), actually implementing a feature is a pretty essential process for helping me develop an intuition about the logic in a way that I can defend and maintain. I can obviously read and review other people’s code, but I think everyone would agree it’s just harder than reasoning about things you’ve typed out yourself.
Claude Code’s plan mode is essential. After specifying something like a ticket description, it will go and peek around the repo to validate assumptions its planning on making. It usually asks 2-3 clarifying questions with decent prefilled recommendations, then goes off to implement it. I only task these models with stuff that is well defined and something I could reasonably do in ~1 hour, but Claude Code is getting a like ~80% success rate on my requests with solutions that are “good enough.”
I’ve definitely been in the camp of thinking “something big has changed and I’m very uncertain about the future” due to AI for the past ~1.5 years. But I’ve had many more moments of genuine amazement the past 3 months than since GPT-4o came out. Areas outside of coding are also finally starting to see more definitive examples of stuff that many people in the 2010s would have said would be unlikely to be achieved by 2025.
The progress in math on AI driven/assisted proof formalization is nothing short of amazing. Though nothing actually consequential has been proven this way as far as I understand it (well the formalization of a chunk of the Prime Number Theorem probably counts), I am amazed at how few people I see talking about what this will eventually lead to. I think it’s unlikely these systems will just top out here, so with some rate of increasing capabilities paired with larger scale efforts to set up advanced scaffolds/environments for the models, it feels likely we’ll see a staggering amount of things formalized very soon.
On the more worrying side, cyber capabilities are rising fast. Anthropic’s recent post about automated exploit discovery in smart contracts seems like a harbinger of what is soon to come. There is a ton of security by obscurity across the web, and I think these agentic systems will tear through a lot of that protection. While defenses will improve as well, I think in the short-term significant harm will be done as many organizations will continue to think of security risks in a “business as usual” way.
Thus continues the pattern of the world moving fast and changing faster. I really don’t know how to predict much of anything about what things will look like in 2, 5, or 10 years. But at least we have some sick coding tools now ¯\_(ツ)_/¯